#FactCheck - Afghan Cricket Team's Chant Misrepresented in Viral Video
Executive Summary:
Footage of the Afghanistan cricket team singing ‘Vande Mataram’ after India’s triumph in ICC T20 WC 2024 exposed online. The CyberPeace Research team carried out a thorough research to uncover the truth about the viral video. The original clip was posted on X platform by Afghan cricketer Mohammad Nabi on October 23, 2023 where the Afghan players posted the video chanting ‘Allah-hu Akbar’ after winning the ODIs in the World Cup against Pakistan. This debunks the assertion made in the viral video about the people chanting Vande Mataram.

Claims:
Afghan cricket players chanted "Vande Mataram" to express support for India after India’s victory over Australia in the ICC T20 World Cup 2024.

Fact Check:
Upon receiving the posts, we analyzed the video and found some inconsistency in the video such as the lip sync of the video.
We checked the video in an AI audio detection tool named “True Media”, and the detection tool found the audio to be 95% AI-generated which made us more suspicious of the authenticity of the video.


For further verification, we then divided the video into keyframes. We reverse-searched one of the frames of the video to find any credible sources. We then found the X account of Afghan cricketer Mohammad Nabi, where he uploaded the same video in his account with a caption, “Congratulations! Our team emerged triumphant n an epic battle against ending a long-awaited victory drought. It was a true test of skills & teamwork. All showcased thr immense tlnt & unwavering dedication. Let's celebrate ds 2gether n d glory of our great team & people” on 23 Oct, 2023.

We found that the audio is different from the viral video, where we can hear Afghan players chanting “Allah hu Akbar” in their victory against Pakistan. The Afghan players were not chanting Vande Mataram after India’s victory over Australia in T20 World Cup 2014.
Hence, upon lack of credible sources and detection of AI voice alteration, the claim made in the viral posts is fake and doesn’t represent the actual context. We have previously debunked such AI voice alteration videos. Netizens must be careful before believing misleading information.
Conclusion:
The viral video claiming that Afghan cricket players chanted "Vande Mataram" in support of India is false. The video was altered from the original video by using audio manipulation. The original video of Afghanistan players celebrating victory over Pakistan by chanting "Allah-hu Akbar" was posted in the official Instagram account of Mohammad Nabi, an Afghan cricketer. Thus the information is fake and misleading.
- Claim: Afghan cricket players chanted "Vande Mataram" to express support for India after the victory over Australia in the ICC T20 World Cup 2024.
- Claimed on: YouTube
- Fact Check: Fake & Misleading
Related Blogs

Introduction
The ‘Barbie’ fever is going high in India, and it’s hype to launch online scams in India. The cybercriminals attacking the ‘Barbie’ fans in India, as the popular malware and antivirus protection MacAfee has recently reported that India is in the top 3rd number among countries facing major malware attacks. After the release of ‘barbie’ in theatres, the Scams started spreading across India through the free download of the ‘Barbie’ movie from the link and other viruses. The scammers trick the victims by selling free ‘Barbie’ tickets and, after the movie’s hit, search for the free download links on websites which leads to the Scams.
What is the ‘Barbie’ malware?
After the release of the ‘Barbie’ movie, trying to keep up with the trend, Barbie fans started to search the links for free movie downloads from anonymous sources. And after downloading the movie, there was malware in the downloaded zip files. The online scam includes not genuine dubbed downloads of the movie that install malware, barbie-related viruses, and fake videos that point to free tickets, and also clicking on unverified links for the movie access resulted in Scam. It is important not to get stuck in these trends just because to keep up with them, as it could land you in trouble.
Case: As per the report of McAfee, several cases of malware trick victims into downloading the ‘ Barbie’ movie in different languages. By clicking the link, it prompts the user to download a Zip file, which is packed with malware
Countries-wise malware distribution
Cyber Scams witnessed a significant surge in just a few weeks, with hundreds of incidents of new malware cases. And The USA is on the top No. Among all the countries, In the USA there was 37 % of ‘Barbie’ malware attacks held per the, while Australia, the UK, and India suffered 6 % of malware attacks. And other countries like Japan, Ireland, and France faced 3% of Malware attacks.
What are the precautions?
Cyber scams are evolving everywhere, users must remain vigilant and take necessary precautions to protect their personal information. The user shall avoid clicking on suspicious links, also those which are related to unauthorised movie downloads or fake ticket offers. The people shall use legitimate and official platforms to access movie-related content. Keeping anti-malware and antivirus will add an extra layer of protection.
Here are some following precautions against Malware:
- Use security software.
- Use strong passwords and authentication.
- Enforce safe browsing and email.
- Data backup.
- Implement Anti-lateral Movement.
Conclusion
Cyberspace is evolving, and with that, Scams are also evolving. With the new trend of ‘Barbie’ Scams going on the rise everywhere, India is on top 3rd No. In India, McAfee reported several malicious attacks that attempted to trick the victims into downloading the free version of ‘Barbie’ movie in dubbed languages. This resulted in a Scam. People usually try to keep up with trends that land them in trouble. The users shall beware of these kinds of cyber-attacks. These scams result in huge losses. Technology should be used with proper precautions as per the incidents happening around.

Introduction
In the evolving landscape of cybercrime, attackers are not only becoming more sophisticated in their approach but also more adept in their infrastructure. The Indian Cybercrime Coordination Centre (I4C) has issued a warning about the use of ‘disposable domains’ by cybercriminals. These are short-lived websites designed tomimic legitimate platforms, deceive users, and then disappear quickly to avoid detection and legal repercussions.
Although they may appear harmless at first glance, disposable domains form the backbone of countless online scams, phishing campaigns, malware distributionschemes, and disinformation networks. Cybercriminals use them to host fake websites, distribute malicious files, send deceptive emails, and mislead unsuspecting users, all while evading detection and takedown efforts.
As India’s digital economy grows and more citizens, businesses, and public services move online, it is crucial to understand this hidden layer of cybercrime infrastructure.Greater awareness among individuals, enterprises, and policymakers is essential to strengthen defences against fraud, protect users from harm, and build trust in thedigital ecosystem
What Are Disposable Domains?
A disposable domain is a website domain that is registered to be used temporarily, usually for hours or days, typically to evade detection or accountability.
These domains are inexpensive, easy to obtain, and can be set up with minimal information. They are often bought in bulk through domain registrars that do not strictly verify ownership information, sometimes using stolen credit cards or cryptocurrencies to remain anonymous. They differ from legitimate temporary domains used for testing or development in one significant aspect, which is ‘purpose’. Cybercriminals use disposable domains to carry out malicious activities such as phishing, sextortion, malware distribution, fake e-commerce sites, spam email campaigns, and disinformation operations.
How Cybercriminals Utilise Disposable Domains
1. Phishing & Credential Stealing: Attackers tend to register lookalike domains that are similar to legitimate websites (e.g., go0gle-login[.]com or sbi-verification[.]online) and trick victims into entering their login credentials. These domains will be active only long enough to deceive, and then they will disappear.
2. Malware Distribution: Disposable domains are widely used for ransomware and spyware operations for hosting malicious files. Because the domains are temporary, threat intelligence systems tend to notice them too late.
3. Fake E-Commerce & Investment Scams: Cyber crooks clone legitimate e-commerce or investment sites, place ad campaigns, and trick victims into "purchasing" goods or investing in scams. The domain vanishes when the scam runs out.
4. Spam and Botnets: Disposable domains assist in botnet command-and-control activities. They make it more difficult for defenders to block static IPs or trace the attacker's infrastructure.
5. Disinformation and Influence Campaigns: State-sponsored actors and coordinated troll networks use disposable domains to host fabricated news articles, fake government documents, and manipulated videos. When these sites are detected and taken down, they are quickly replaced with new domains, allowing the disinformation cycle to continue uninterrupted.
Why Are They Hard to Stop?
Registering a domain is inexpensive and quick, often requiring no more than an email address and payment. The difficulty is the easy domain registrations and the absence of worldwide enforcement. Domain registrars differ in enforcing Know-Your-Customer (KYC) standards stringently. ICANN (Internet Corporation for Assigned Names and Numbers) has certain regulations in place but enforcement is inconsistent. ICANN does require registrars to maintain accurate Who is information (the “Registrant Data Accuracy Policy”) and to act on abuse complaints. However, ICANN is not an enforcement agency. It oversees contracts with registrars but cannot directly police every registration. Cybercriminals exploit services such as:
- Privacy protection shields that conceal actual WHOIS information.
- Bulletproof hosting that evades takedown notices.
- Fast-flux DNS methods to rapidly alter IP addresses
Additionally, utilisation of IDNs ( Internationalised Domain Names) and homoglyph attacks enables the attackers to register visually similar domains to legitimate ones (e.g., using Cyrillic characters to represent Latin ones).
Real-World Example: India and the Rise of Fake Investment Sites
India has witnessed a wave of monetary scams that are connected with disposable domains. Over hundreds of false websites impersonating government loan schemes, banks or investment websites, and crypto-exchanges were found on disposable domains such as gov-loans-apply[.]xyz, indiabonds-secure[.]top, or rbi-invest[.]store. Most of them placed paid advertisements on sites such as Facebook or Google and harvested user information and payments, only to vanish in 48–72 hours. Victims had no avenue of proper recourse, and the authorities were left with a digital ghost trail.
How Disposable Domains Undermine Cybersecurity
- Bypass Blacklists: Dynamic domains constantly shifting evade static blacklists.
- Delay Attribution: Time is wasted pursuing non-existent owners or takedowns.
- Mass Targeting: One actor can register thousands of domains and attack at scale.
- Undermine Trust: Frequent users become targets when genuine sites are duplicated and it looks realistic.
Recommendations Addressing Legal and Policy Gaps in India
1. There is a need to establish a formal coordination mechanism between domain registrars and national CERTs such as CERT-In to enable effective communication and timely response to domain-based threats.
2. There is a need to strengthen the investigative and enforcement capabilities of law enforcement agencies through dedicated resources, training, and technical support to effectively tackle domain-based scams.
3. There is a need to leverage the provisions of the Digital Personal Data Protection Act, 2023 to take action against phishing websites and malicious domains that collect personal data without consent.
4. There is a need to draft and implement specific regulations or guidelines to address the misuse of digital infrastructure, particularly disposable and fraudulent domains, and close existing regulatory gaps.
What Can Be Done: CyberPeace View
1. Stronger KYC for Domain Registrations: Registrars selling domains to Indian users or based in India should conduct verified KYC processes, with legal repercussions for carelessness.
2. Real-Time Domain Blacklists: CERT-In, along with ISPs and hosting companies, should operate and enforce a real-time blacklist of scam domains known.
3. Public Reporting Tools: Observers or victims should be capable of reporting suspicious domains through an easy interface (tied to cybercrime.gov.in).
4. Collaboration with Tech Platforms: Social media services and online ad platforms should filter out ads associated with disposable or spurious domains and report abuse data to CERT-In.
5. User Awareness: Netizens should be educated to check URLs thoroughly, not click on unsolicited links and they must verify the authenticity of websites.
Conclusion
Disposable domains have silently become the foundation of contemporary cybercrime. They are inexpensive, highly anonymous, and short-lived, which makes them a darling weapon for cybercriminals ranging from solo spammers to nation-state operators. In an increasingly connected Indian society where the penetration rate of internet users is high, this poses an expanding threat to economic security, public confidence, and national resilience. Combating this problem will need a combination of technical defences, policy changes, public-private alliances, and end-user sensitisation. As India develops a Cyber Secure Bharat, monitoring and addressing disposable domain abuse must be the utmost concern.
References
- https://www.bitcot.com/disposable-domains
- https://atdata.com/blog/evolution-of-email-fraud-rise-of-hyper-disposable-domains/
- https://www.cyfirma.com/research/scamonomics-the-dark-side-of-stock-crypto-investments-in-india/
- https://knowledgebase.constantcontact.com/lead-gen-crm/articles/KnowledgeBase/50330-Understanding-Blocked-Forbidden-and-Disposable-Domains?lang=en_US
- https://www.meity.gov.in/
- https://intel471.com/blog/bulletproof-hosting-fast-flux-dns-double-flux-vps

Executive Summary
Following the results of the recent West Bengal elections, a video of former Chief Election Commissioner Rajiv Kumar has gone viral on social media. In the clip, Kumar is seen questioning television news channels over their election-result coverage and alleged early “trends” before the actual counting process begins. In the viral video, Rajiv Kumar can be heard saying, “When counting begins, channels start showing trends from 8:05 AM itself, which is nonsense. The first round of counting starts only at 8:30 AM. We have evidence that leads were being shown before that. Is it possible that these early trends are shown just to justify exit polls?”The video is being widely shared with the claim that Kumar made these remarks after the recently concluded West Bengal Assembly elections Research conducted by CyberPeace Research Wing found that a 2024 video of former Chief Election Commissioner Rajiv Kumar is being misleadingly shared as a recent statement made after the West Bengal election results.
Claim
An Instagram user shared the viral clip suggesting that the former Election Commissioner made these comments in the context of the latest West Bengal poll results.
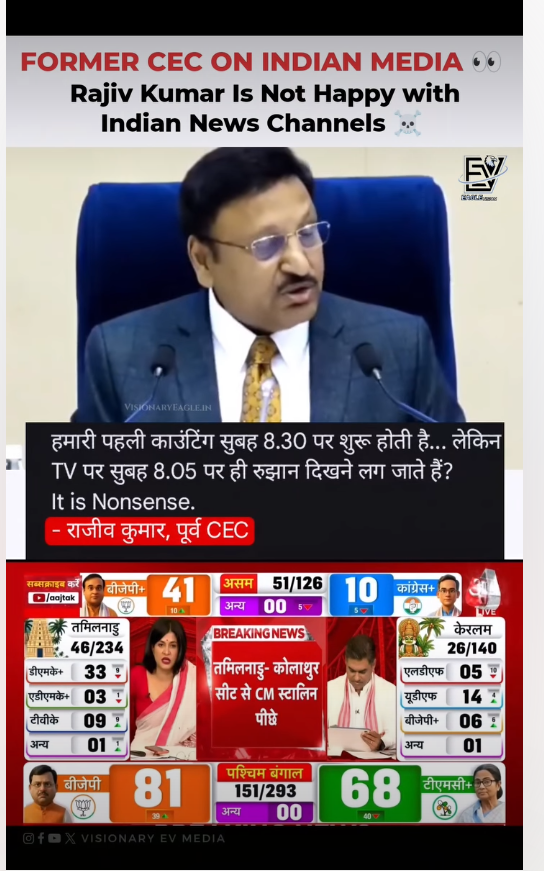
Fact Check
Using relevant keyword searches, we traced the original source of the clip to an official post shared by the Election Commission of Indiaon Facebook on October 15, 2024. The video was part of a press conference announcing the Assembly election schedule for Maharashtra and Jharkhand.

We also found the complete live-streamed press conference on the official YouTube channel of the Election Commission.

During the press conference, around the 26:45-minute mark, an ANI journalist referred to discrepancies between exit polls and actual Lok Sabha election results and asked whether such situations fuel doubts over EVMs among the public. Responding to the question at around 30:27 minutes, Rajiv Kumar spoke about the need for self-regulation in electronic media and concerns over premature “trends” shown during counting day. He said that exit polls often create public expectations despite lacking a clear scientific basis and questioned why TV channels begin displaying leads even before the first official counting round starts.
Conclusion
The viral claim is misleading. The video of former Chief Election Commissioner Rajiv Kumar is not related to the recent West Bengal election results. The clip is from an October 15, 2024 press conference held to announce the Maharashtra and Jharkhand Assembly election schedule and is now being falsely shared in a misleading context after the West Bengal polls.