#FactCheck - AI-Generated Video Falsely Claims Salman Khan Is Joining AIMIM
A video of Bollywood actor Salman Khan is being widely circulated on social media, in which he can allegedly be heard saying that he will soon join Asaduddin Owaisi’s party, the All India Majlis-e-Ittehadul Muslimeen (AIMIM). Along with the video, a purported image of Salman Khan with Asaduddin Owaisi is also being shared. Social media users are claiming that Salman Khan is set to join the AIMIM party.
CyberPeace research found the viral claim to be false. Our research revealed that Salman Khan has not made any such statement, and that both the viral video and the accompanying image are AI-generated.
Claim
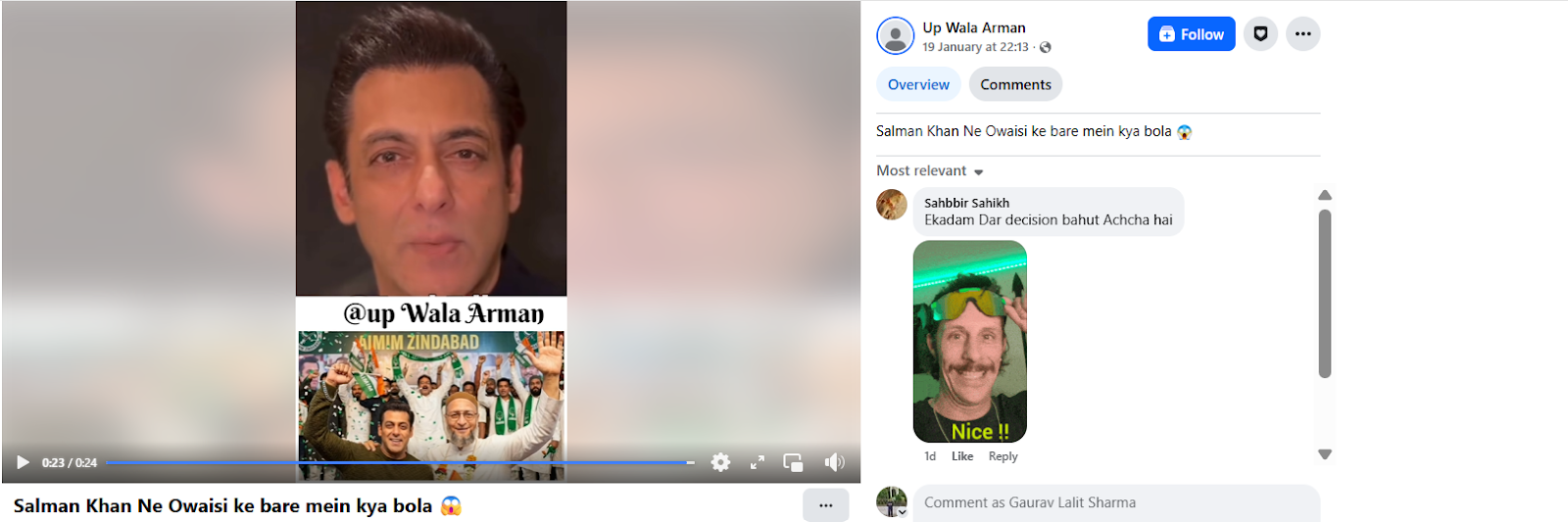
Social media users claim that Salman Khan has announced his decision to join AIMIM.On 19 January 2026, a Facebook user shared the viral video with the caption, “What did Salman say about Owaisi?” In the video, Salman Khan can allegedly be heard saying that he is going to join Owaisi’s party. (The link to the post, its archived version, and screenshots are available.)
Fact Check:
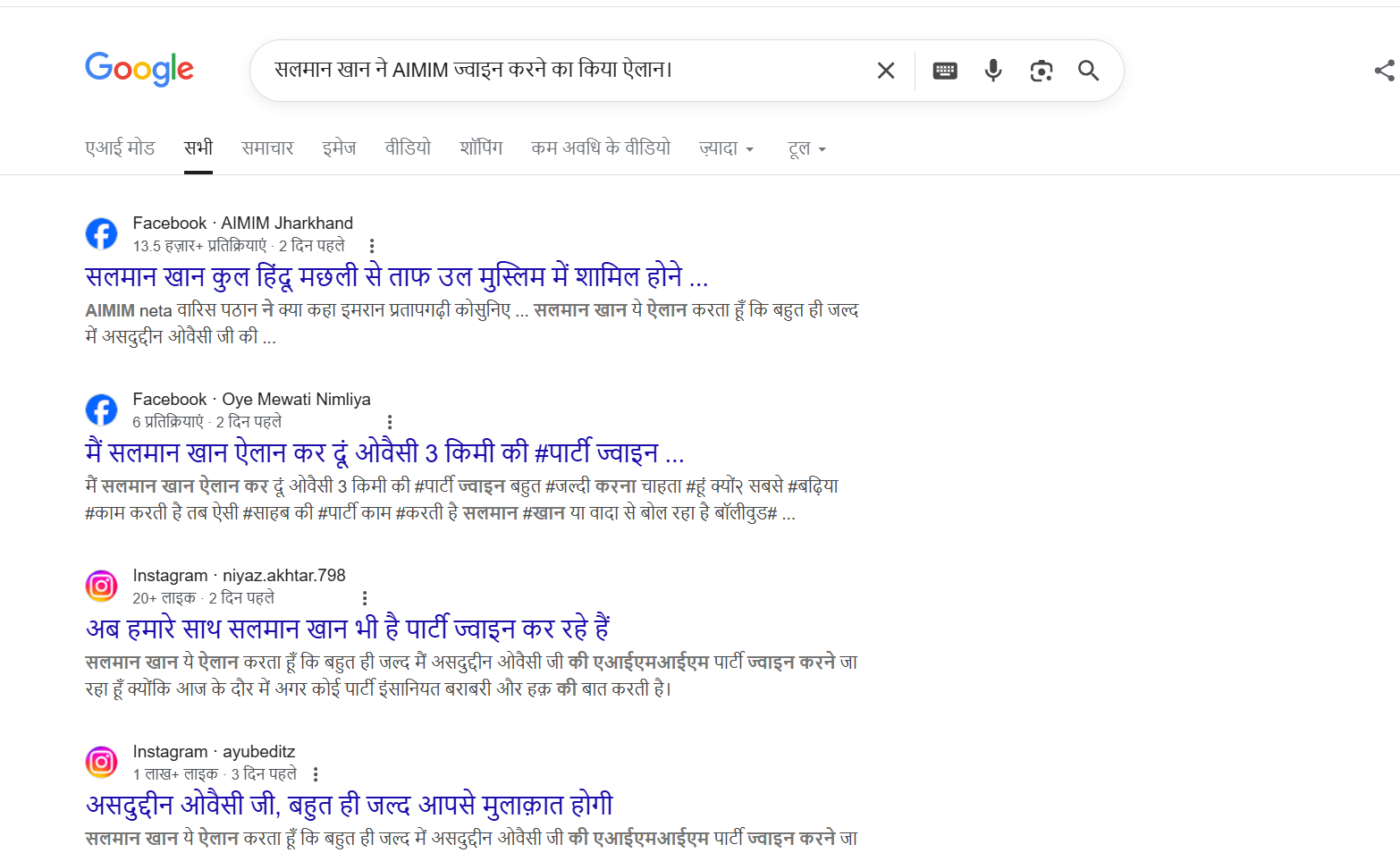
To verify the claim, we first searched Google using relevant keywords. However, no credible or reliable media reports were found supporting the claim that Salman Khan is joining AIMIM.
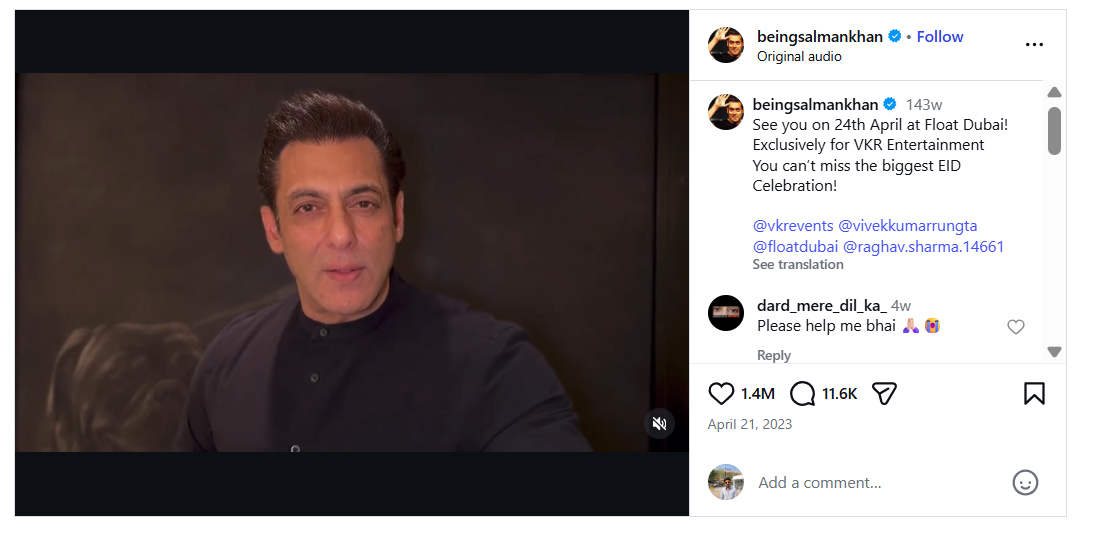
In the next step of verification, we extracted key frames from the viral video and conducted a reverse image search using Google Lens. This led us to a video posted on Salman Khan’s official Instagram account on 21 April 2023. In the original video, Salman Khan is seen talking about an event scheduled to take place in Dubai. A careful review of the full video confirmed that no statement related to AIMIM or Asaduddin Owaisi is made.
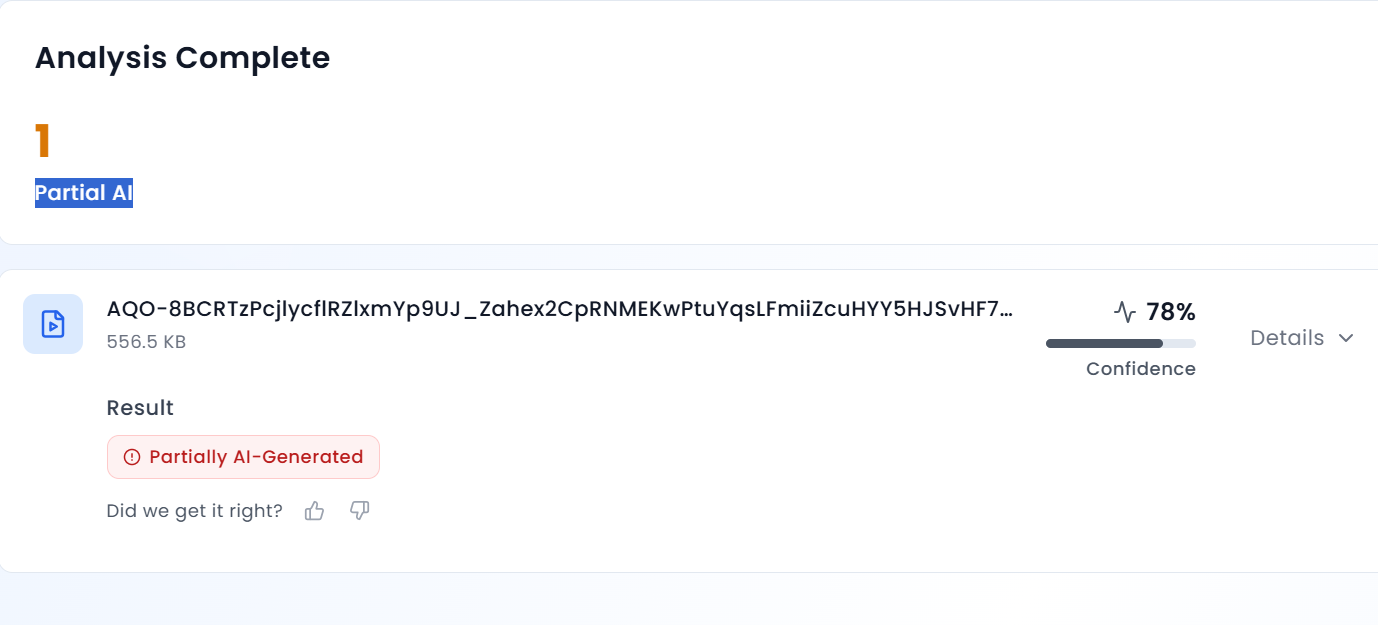
Further analysis of the viral clip revealed that Salman Khan’s voice sounds unnatural and robotic. To verify this, we scanned the video using AURGIN AI, an AI-generated content detection tool. According to the tool’s analysis, the viral video was generated using artificial intelligence.
Conclusion
Salman Khan has not announced that he is joining the AIMIM party. The viral video and the image circulating on social media are AI-generated and manipulated.
Related Blogs

Executive Summary
A news graphic is being widely shared on social media claiming that Union Education Minister Dharmendra Pradhan will resign on July 22. The graphic quotes him as saying, "Respecting the sentiments of the country's youth, I have taken this decision." CyberPeace Research Wing ’s research found the claim to be false. The probe revealed that no official announcement has been made regarding Dharmendra Pradhan’s resignation as Union Education Minister. However, demands for his resignation have intensified from opposition parties and student groups over alleged irregularities in NEET and other examinations, leading to protests in Delhi and other places. The research also found that the viral news graphic circulating on social media was likely created using Artificial Intelligence (AI).
Claim:
A social media user on Instagram shared the viral news graphic on July 21, 2026, claiming that Union Education Minister Dharmendra Pradhan is set to resign on July 22. The post also claimed that Pradhan said during a press conference, "Respecting the sentiments of the country's youth, I have taken this decision."
https://www.instagram.com/reel/DbEMoRtgLfT/?igsh=c3g3dzZxZ2U3YW01

Fact Check:
To verify the authenticity of the viral claim, we conducted a Google search using relevant keywords. However, we did not find any credible media reports confirming that Union Education Minister Dharmendra Pradhan is resigning on July 22.Further, we examined the official X (formerly Twitter) account of Union Education Minister Dharmendra Pradhan. No official announcement or post related to his resignation was found on his account.
https://x.com/dpradhanbjp?lang=en
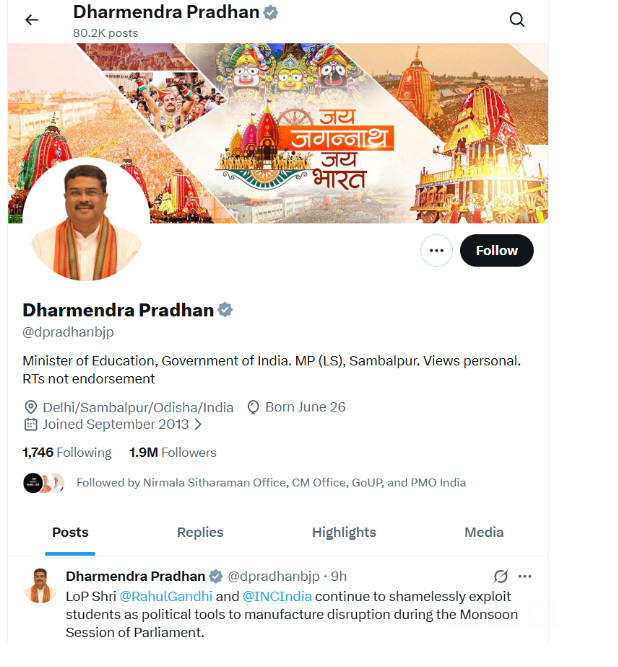
Upon examining the viral news graphic, we noticed several indicators suggesting that it could be AI-generated. To verify this, we analysed the graphic using the AI detection tool AI or Not. The tool’s analysis indicated a 94% probability that the graphic was generated using AI.
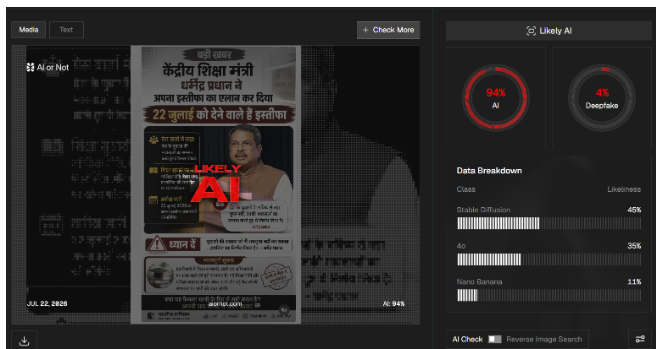
We also scanned the viral graphic through another AI detection tool, WasIt AI. According to the tool’s results, the probability of the graphic being AI-generated was found to be 87%.
Conclusion:
CyberPeace Research Wing ’s fact check found the viral claim to be false. No official announcement has been made regarding Union Education Minister Dharmendra Pradhan’s resignation, and reports claiming that he will resign on July 22 are incorrect. The research further revealed that the viral news graphic circulating on social media was created using Artificial Intelligence (AI).

Executive Summary
A video of US Secretary of State Marco Rubio is rapidly going viral on social media, in which he can allegedly be heard making a statement regarding the 2025 India-Pakistan conflict. Along with the video, it is being claimed that the US played a crucial role in ending the conflict between the two countries, but India was the first to initiate a ceasefire with Pakistan. Users are sharing this video believing it to be true.
Research by the CyberPeace Research Wing revealed that the video has been digitally manipulated. Rubio did state that the United States played a role in ending the conflict, but he never said that India was the first to request a ceasefire from Pakistan. This alleged statement was not part of the original video and was added later to alter the clip.
Claim
A user on a Facebook page shared the viral video and wrote, "Marco Rubio's statement has clearly brought out the truth, weakening India's claim. During 'Maarka-e-Haq', after suffering heavy losses, India was the first party to request a ceasefire from Pakistan. This highlights the gap between India's public claims and the ground reality, where the military..." The post link, archive link, and screenshot can be seen below. https://www.facebook.com/reel/1015648544746728
https://www.facebook.com/reel/1015648544746728
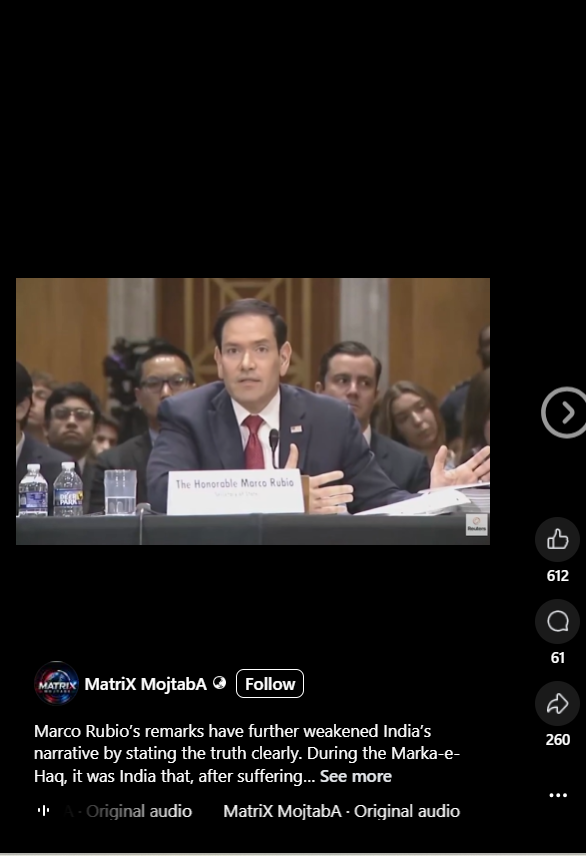
Fact Check
We investigated the viral video using the InVid tool and extracted several of its keyframes. These keyframes were then subjected to a reverse image search via Google Lens. The investigation revealed that the exact same video had been shared on social media previously, showing the same background and setting. The post link and screenshot can be seen below.
https://www.facebook.com/reel/1015648544746728

In the next step of our investigation, we found a video published on Reuters' official YouTube channel on June 2, 2026, whose background matches the viral video. However, nowhere in this original video is Marco Rubio heard saying that India was the first to request a ceasefire from Pakistan. The post link and screenshot can be seen below.
https://www.youtube.com/watch?v=qSpp5IYO6Cs

At the 2-hour 8-minute 55-second mark of the Reuters video, Rubio only states that the US played a role in ending the India-Pakistan conflict. Following this, he discusses the Thailand-Cambodia conflict. This makes it clear that the alleged statement in the viral video was digitally added or edited in, and is not part of the original footage.
Taking the investigation further, we scanned the suspicious audio portion of the viral video using the AI detection tool 'Resemble AI'. According to the analysis results, clear signs of audio manipulation were detected.
Conclusion:
Our investigation revealed that the video has been digitally manipulated. Rubio did state that the United States played a role in ending the conflict, but he never said that India was the first to request a ceasefire from Pakistan. This alleged statement was not part of the original video and was altered by adding it later.

Executive Summary:
A photo claiming that Mr. Rowan Atkinson, the famous actor who played the role of Mr. Bean, lying sick on bed is circulating on social media. However, this claim is false. The image is a digitally altered picture of Mr.Barry Balderstone from Bollington, England, who died in October 2019 from advanced Parkinson’s disease. Reverse image searches and media news reports confirm that the original photo is of Barry, not Rowan Atkinson. Furthermore, there are no reports of Atkinson being ill; he was recently seen attending the 2024 British Grand Prix. Thus, the viral claim is baseless and misleading.

Claims:
A viral photo of Rowan Atkinson aka Mr. Bean, lying on a bed in sick condition.



Fact Check:
When we received the posts, we first did some keyword search based on the claim made, but no such posts were found to support the claim made.Though, we found an interview video where it was seen Mr. Bean attending F1 Race on July 7, 2024.

Then we reverse searched the viral image and found a news report that looked similar to the viral photo of Mr. Bean, the T-Shirt seems to be similar in both the images.

The man in this photo is Barry Balderstone who was a civil engineer from Bollington, England, died in October 2019 due to advanced Parkinson’s disease. Barry received many illnesses according to the news report and his application for extensive healthcare reimbursement was rejected by the East Cheshire Clinical Commissioning Group.
Taking a cue from this, we then analyzed the image in an AI Image detection tool named, TrueMedia. The detection tool found the image to be AI manipulated. The original image is manipulated by replacing the face with Rowan Atkinson aka Mr. Bean.

{kind=link}


Hence, it is clear that the viral claimed image of Rowan Atkinson bedridden is fake and misleading. Netizens should verify before sharing anything on the internet.
Conclusion:
Therefore, it can be summarized that the photo claiming Rowan Atkinson in a sick state is fake and has been manipulated with another man’s image. The original photo features Barry Balderstone, the man who was diagnosed with stage 4 Parkinson’s disease and subsequently died in 2019. In fact, Rowan Atkinson seemed perfectly healthy recently at the 2024 British Grand Prix. It is important for people to check on the authenticity before sharing so as to avoid the spreading of misinformation.
- Claim: A Viral photo of Rowan Atkinson aka Mr. Bean, lying on a bed in a sick condition.
- Claimed on: X, Facebook
- Fact Check: Fake & Misleading