The Case for Pseudonymisation: From Data Power to Digital Trust
Introduction
In today’s digital world, data has emerged as the new currency that influences global politics, markets, and societies. Companies, governments, and tech behemoths aim to control data because it accords them influence and power. However, a fundamental challenge brought about by this increased reliance on data is how to strike a balance between privacy protection and innovation and utility.
In recognition of these dangers, more than 200 Nobel laureates, scientists, and world leaders have recently signed the Global Call for AI Red Lines. Governments are urged by this initiative to create legally binding international regulations on artificial intelligence by 2026. Its goal is to stop AI from going beyond moral and security bounds, particularly in areas like political manipulation, mass surveillance, cyberattacks, and dangers to democratic institutions.
One way to address the threat to privacy is through pseudonymization, which makes it possible to use data valuable for research and innovation by substituting personal identifiers for artificial ones. Pseudonymization thus directly advances the AI Red Lines initiative's mission of facilitating technological advancement while lowering the risks of data misuse and privacy violations.
The Red Lines of AI: Why do they matter?
The Global Call for AI Red Lines initiative represents a collective attempt to impose precaution before catastrophe, which was done with the objective of recognising the Red Lines in the use of AI tools. Thus, anything that unites the risks of using AI is due to the absence of global safeguards. Some of these Red Lines can be understood as;
- Cybersecurity breaches in the form of exposure of financial and personal data due to AI-driven hacking and surveillance.
- Occurrence of privacy invasions due to endless tracking.
- Generative AI can also help to create realistic fake content, undermining the trust of public discourses, leading to misinformation.
- Algorithmic amplification of polarising content can also threaten civic stability, leading to a demographic disruption.
Legal Frameworks and Regulatory Landscape
The regulations of Artificial Intelligence stand fragmented across jurisdictions, leaving significant loopholes aside. Some of the frameworks already provide partial guidance. The European Union’s Artificial Intelligence Act 2024 bans “unacceptable” AI practices, whereas the US-China Agreement also ensures that nuclear weapons remain under human, not machine-controlled. The UN General Assembly has adopted resolutions urging safe and ethical AI usage, with a binding and elusive global treaty.
On the front of data protection, the General Data Protection Regulations (GDPR) of EU offers a clear definition of Pseudonymisation under Article 4(5). It also describes a process where personal data is altered in a way that it cannot be attributed to an individual without additional information, which must be stored securely and separately. Importantly, pseudonymised data still qualifies as “personal data” under GDPR. However, India’s Digital Personal Data Protection Act (DPDP) 2023 adopts a similar stance. It does not explicitly define pseudonymisation in broad terms, such as “personal data” by including potentially reversible identifiers. According to Section 8(4) of the Act, companies are meant to adopt appropriate technical or organisational measures. International bodies and conventions like the OECD Principles on AI or the Council of Europe Convention 108+ emphasize accountability, transparency, and data minimisation. Collectively, these instruments point towards pseudonymization as a best practice, though interpretations of its scope differ.
Strategies for Corporate Implementation
For a company, pseudonymisation is not just about compliance, it is also a practical solution that offers measurable benefits. By pseudonymising data, businesses can get benefits, such as;
- Enhancing Privacy protection by masking identifiers like names or IDs by reducing the impact of data breaches.
- Preserving Data Utility, unlike having a full anonymisation, pseudonymisation also retains patterns that are essential for analytical innovation.
- Facilitating data sharing can allow organizations to collaborate with their partners and researchers while maintaining proper trust.
According to these benefits, competitive advantages get translated to clauses where customers find it more likely to trust organizations that prioritise data protection, while pseudonymisation further enables the firms to engage in cross-border collaboration without violating local data laws.
Balancing Privacy Rights and Data Utility
Balancing is a central dilemma; on one side lies the case of necessity over data utility, where companies, researchers and governments rely on large datasets to enhance the scale of AI innovation. On the other hand lies the question of the right to privacy, which is a non-negotiable principle protected under the international human rights law.
Pseudonymisation offers a practical compromise by enabling the use of sensitive data while reducing the privacy risks. Taking examples of different domains, such as healthcare, it allows the researchers to work with patient information without exposing identities, whereas in finance, it supports fraud detection without revealing the customer details.
Conclusion
The rapid rise of artificial intelligence has led to the outpacing of regulations, raising urgent questions related to safety, fairness and accountability. The global call for recognising the AI red lines is a bold step that looks in the direction of setting universal boundaries. Yet, alongside the remaining global treaties, practical safeguards are also needed. Pseudonymisation exemplifies such a safeguard, which is legally recognised under the GDPR and increasingly relevant in India’s DPDP Act. It balances the twin imperatives of privacy, protection, and data utility. For organizations, adopting pseudonymisation is not only about ensuring regulatory compliance, rather, it is also about building trust, ensuring resilience, and aligning with the broader ethical responsibilities in this digital age. As the future of AI is debatable, the guiding principles also need to be clear. By embedding techniques for preserving privacy, like pseudonymisation, into AI systems, we can take a significant step towards developing a sustainable, ethical and innovation-driven digital ecosystem.
References
https://www.techaheadcorp.com/blog/shadow-ai-the-risks-of-unregulated-ai-usage-in-enterprises/
https://planetmainframe.com/2024/11/the-risks-of-unregulated-ai-what-to-know/
https://cepr.org/voxeu/columns/dangers-unregulated-artificial-intelligence
https://www.forbes.com/sites/bernardmarr/2023/06/02/the-15-biggest-risks-of-artificial-intelligence/
Related Blogs

Executive Summary
As India concluded its 77th Republic Day celebrations on January 26, 2026, with grandeur and patriotic enthusiasm along the iconic Kartavya Path, a video began circulating on social media claiming to show Indian security personnel failing to perform motorcycle stunts during the ceremonial parade. The short clip allegedly depicts soldiers attempting high-risk, synchronised motorcycle manoeuvres, only to lose balance and fall off their bikes. The visuals were widely shared online with mocking captions, suggesting incompetence during a nationally televised event. However, an research by the CyberPeace found that the video is not authentic and was digitally generated using artificial intelligence.
Claim
A Pakistan-based X user, Sadaf Baloch (@sadafzbaloch), shared the video on January 27, claiming it showed Indian security personnel failing to execute motorcycle stunts during the Republic Day parade held on January 26, 2026. While sharing the clip, the user wrote:“Every time the Indian Army tries a tactical stunt, it looks less like combat training and more like a low-budget circus trailer filmed in one take.”The post was widely circulated with similar narratives questioning the professionalism of Indian forces.
Here is the link and archive link to the post, along with a screenshot.

To verify the authenticity of the viral video, the Desk conducted a detailed frame-by-frame analysis. During the examination, a watermark linked to ‘Sora’—an AI text-to-video generation model was detected at the 00:05 timestamp. The presence of this watermark strongly indicated that the video was artificially generated and not recorded during a real-world event.

Fact Check:
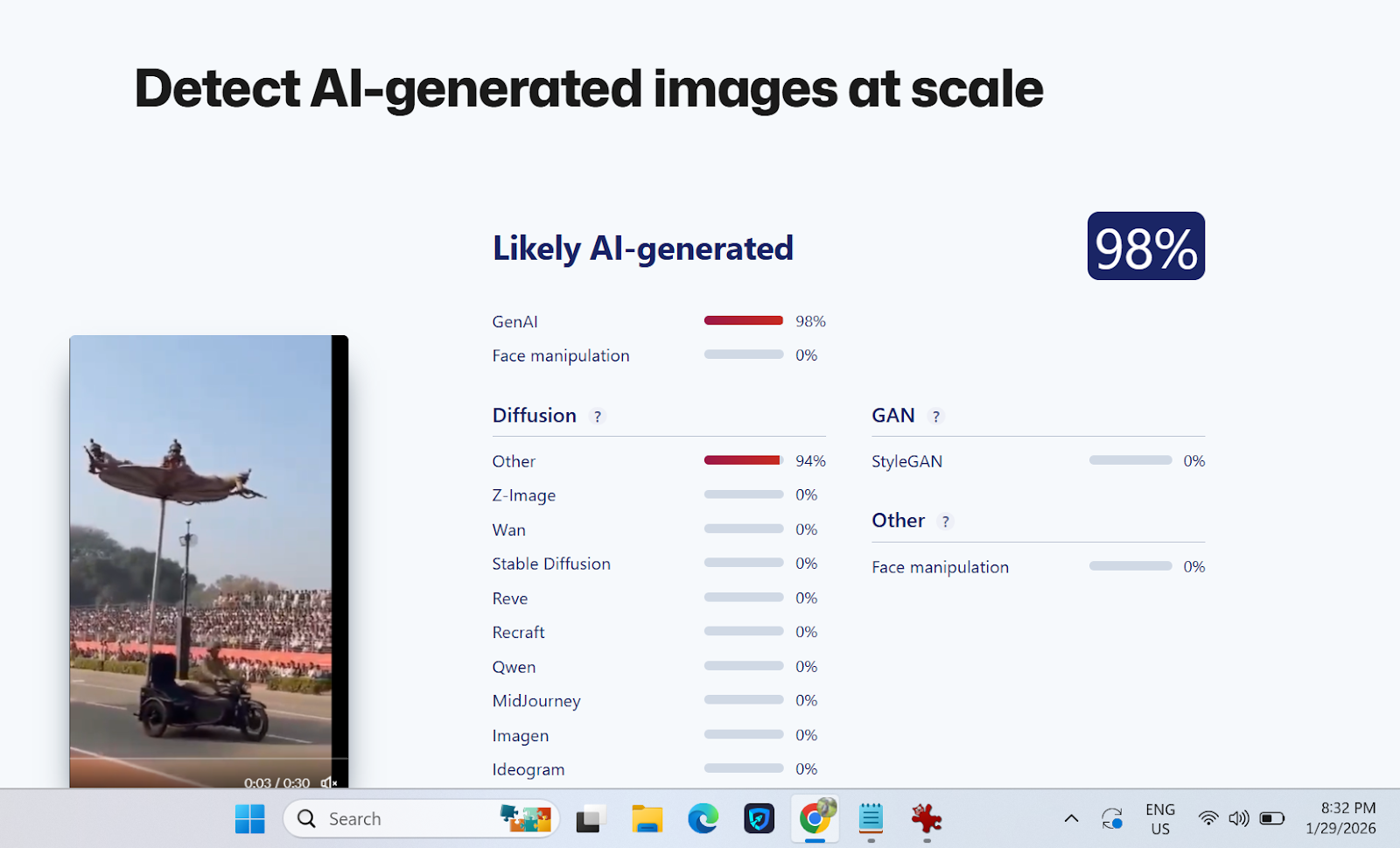
Further visual scrutiny revealed several inconsistencies commonly associated with AI-generated content. The background appeared unnatural and lacked realistic depth, while the movements and reactions of the security personnel looked mechanically exaggerated and inconsistent with real physics. Facial expressions and body motions during the alleged falls also appeared unrealistic. To strengthen the verification, the Desk analysed the clip using Sightengine, an AI-detection tool. The results showed a 98 per cent probability that the video contained AI-generated or deepfake elements.
Below is a screenshot of the result.
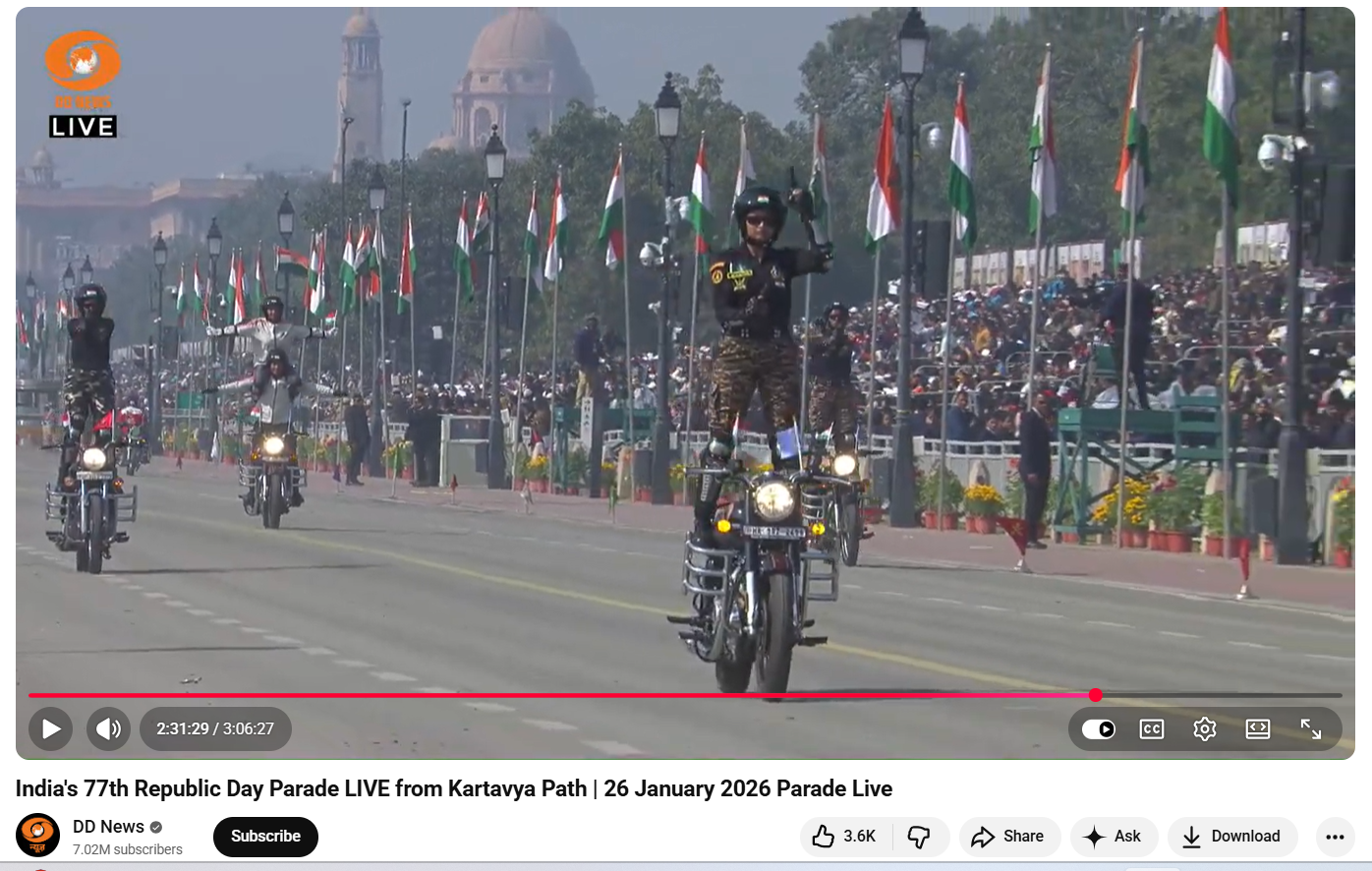
As part of the research , the Desk also conducted a customised keyword search and reviewed official coverage of the Republic Day parade. A full-length video broadcast by DD News on its official YouTube channel was examined. The footage showed joint CRPF and SSB motorcycle teams performing traditional daredevil stunts without any mishap. No incident resembling the viral claim was found in the official broadcast or in any credible media reports.
Here is the video link and a screenshot.
Conclusion
The CyberPeace research confirms that the viral video purportedly showing Indian security personnel failing to perform motorcycle stunts during the 77th Republic Day parade is AI-generated. The clip has been falsely circulated online as genuine content with the intent to mislead viewers and spread misinformation.
.webp)
Introduction
The scam involving "drugs in parcels' has resurfaced again with a new face. Cybercriminals impersonating and acting as FedEx, Police and various other authorities and in actuality, they are the perpetrators or bad actors behind the renewed "drugs in parcel" scam, which entails pressuring victims into sending money and divulging private information in order to escape fictitious legal repercussions.
Modus operandi
The modus operandi followed in this scam usually begins with a hacker calling someone on their cell phone posing as FedEx. They say that they are the recipients of a package under their name that includes illegal goods like jewellery, narcotics, or other items. The victim would feel afraid and apprehensive by now. Then there will be a video call with someone else who is posing as a police officer. The victim will be asked to keep the matter confidential while it is being investigated by this "fake officer."
After the call, they would get falsified paperwork from the CBI and RBI stating that an arrest warrant had been issued. Once the victim has fallen entirely under their sway, they would claim that the victim's Aadhaar has been used to carry out the unlawful conduct. They then request that the victim submit their bank account information and Aadhaar data for investigation. Subsequently, the hackers request that the victim transfer funds to a bank account for RBI validation. The victims thus submit money to the hackers believing it to be true for clearing their name.
Recent incidence:
In the most recent instance of a "drug-in-parcel" scam, an IT expert in Pune was defrauded of Rs 27.9 lakh by internet con artists acting as members of the Mumbai police's Cyber Crime Cell. The victim filed the First Information Report (FIR) in this matter at the police station. The victim stated that on November 11, 2023, the complainant received a call from a fraudster posing as a Mumbai police Cyber Crime Cell officer. The scammer falsely claimed to have discovered illegal narcotics in a package addressed to the complainant sent from Mumbai to Taiwan, along with an expired passport and an SBI card. To avoid arrest in a fabricated drug case, the fraudster coerced the complainant into providing bank account information under the guise of "verification." The victim, fearing legal consequences, transferred Rs 27,98,776 in ten online transactions to two separate bank accounts as instructed. Upon realizing the deception, the complainant reported the incident to the police, leading to an investigation.
In another such incident, the victim received an online bogus identity card from the scammers who had phoned him on the phone in October 2023. In an attempt to "clear the case" and issue a "no-objection certificate (NOC)," the fraudster persuaded the victim to wire money to a bank account, claiming to have seized narcotics in a shipment shipped from Mumbai to Thailand under his name. Fraudsters threatened to arrest the victim for mailing the narcotics package if money was not provided.
Furthermore, In August 2023, fraudsters acting as police officers and executives of courier companies defrauded a 25-year-old advertising student of Rs 53 lakh. They extorted money from her under the guise of avoiding legal action, which would include arrest, and informed her that narcotics had been discovered in a package she had delivered to Taiwan. According to the police, callers acting as police officers threatened to arrest the girl and forced her to complete up to 34 transactions totalling Rs 53.63 lakh from her and her mother's bank accounts to different bank accounts.
Measures to protect oneself from such scams
Call Verification:
- Be sure to always confirm the legitimacy of unexpected calls, particularly those purporting to be from law enforcement or delivery services. Make use of official contact information obtained from reliable sources to confirm the information presented.
Confidentiality:
- Use caution while disclosing personal information online or over the phone, particularly Aadhaar and bank account information. In general, legitimate authorities don't ask for private information in this way.
Official Documentation:
- Request official documents via the appropriate means. Make sure that any documents—such as arrest warrants or other government documents—are authentic by getting in touch with the relevant authorities.
No Haste in Transactions:
- Proceed with caution when responding hastily to requests for money or quick fixes. Creating a sense of urgency is a common tactic used by scammers to coerce victims into acting quickly.
Knowledge and Awareness:
- Remain up to date on common fraud schemes and frauds. Keep up with the most recent strategies employed by online fraudsters to prevent falling for fresh scam iterations.
Report Suspicious Activity:
- Notify the local police or other appropriate authorities of any suspicious calls or activities. Reports received in a timely manner can help investigations and shield others from falling for the same fraud.
2fA:
- Enable two-factor authentication (2FA) wherever you can to provide online accounts and transactions an additional degree of protection. This may lessen the chance of unwanted access.
Cybersecurity Software:
- To defend against malware, phishing attempts, and other online risks, install and update reputable antivirus and anti-malware software on a regular basis.
Educate Friends and Family:
- Inform friends and family about typical scams and how to avoid falling victim to fraud. A safer online environment can be achieved through increased collective knowledge.
Be skeptical
- Whenever anything looks strange or too good to be true, it most often is. Trust your instincts. Prior to acting, follow your gut and confirm the information.
By taking these precautions and exercising caution, people may lessen their vulnerability to scams and safeguard their money and personal data from online fraudsters.
Conclusion:
Verifying calls, maintaining secrecy, checking official papers, transacting cautiously, and keeping up to date are all examples of protective measures for protecting ourselves from such scams. Using cybersecurity software, turning on two-factor authentication, and reporting suspicious activity are essential in stopping these types of frauds. Raising awareness and working together are essential to making the internet a safer place and resisting the activities of cybercriminals.
References:
- https://indianexpress.com/article/cities/pune/pune-cybercrime-drug-in-parcel-cyber-scam-it-duping-9058298/#:~:text=In%20August%20this%20year%2C%20a,avoiding%20legal%20action%20including%20arrest.
- https://www.the420.in/pune-it-professional-duped-of-rs-27-9-lakh-in-drug-in-parcel-scam/
- https://www.newindianexpress.com/states/tamil-nadu/2023/oct/16/the-return-of-drugs-in-parcel-scam-2624323.html
- https://timesofindia.indiatimes.com/city/hyderabad/2-techies-fall-prey-to-drug-parcel-scam/articleshow/102786234.cms

Introduction
The recent inauguration of the Google Safety Engineering Centre (GSEC) in Hyderabad on 18th June, 2025, marks a pivotal moment not just for India, but for the entire Asia-Pacific region’s digital future. As only the fourth such centre in the world after Munich, Dublin, and Málaga, its presence signals a shift in how AI safety, cybersecurity, and digital trust are being decentralised, leading to a more globalised and inclusive tech ecosystem. India’s digitisation over the years has grown at a rapid scale, introducing millions of first-time internet users, who, depending on their awareness, are susceptible to online scams, phishing, deepfakes, and AI-driven fraud. The establishment of GSEC is not just about launching a facility but a step towards addressing AI readiness, user protection, and ecosystem resilience.
Building a Safer Digital Future in the Global South
The GSEC is set to operationalise the Google Safety Charter, designed around three core pillars: empowering users by protecting them from online fraud, strengthening government cybersecurity and enterprise, and advancing responsible AI in the platform design and execution. This represents a shift from the standard reactive safety responses to proactive, AI-driven risk mitigation. The goal is to make safety tools not only effective, but tailored to threats unique to the Global South, from multilingual phishing to financial fraud via unofficial lending apps. This centre is expected to stimulate regional cybersecurity ecosystems by creating jobs, fostering public-private partnerships, and enabling collaboration across academia, law enforcement, civil society, and startups. In doing so, it positions Asia-Pacific not as a consumer of the standard Western safety solutions but as an active contributor to the next generation of digital safeguards and customised solutions.
Previous piloted solutions by Google include DigiKavach, a real-time fraud detection framework, and tools like spam protection in mobile operating systems and app vetting mechanisms. What GSEC might aid with is the scaling and integration of these efforts into systems-level responses, where threat detection, safety warnings, and reporting mechanisms, etc., would ensure seamless coordination and response across platforms. This reimagines safety as a core design principle in India’s digital public infrastructure rather than focusing on attack-based response.
CyberPeace Insights
The launch aligns with events such as the AI Readiness Methodology Conference recently held in New Delhi, which brought together researchers, policymakers, and industry leaders to discuss ethical, secure, and inclusive AI implementation. As the world grapples with how to deal with AI technologies ranging from generative content to algorithmic decisions, centres like GSEC can play a critical role in defining the safeguards and governance structures that can support rapid innovation without compromising public trust and safety. The region’s experiences and innovations in AI governance must shape global norms, and the role of Tech firms in doing so is significant. Apart from this, efforts with respect to creating digital infrastructure and safety centres addressing their protection resonate with India’s vision of becoming a global leader in AI.
References
- https://www.thehindu.com/news/cities/Hyderabad/google-safety-engineering-centre-india-inaugurated-in-hyderabad/article69708279.ece
- https://www.businesstoday.in/technology/news/story/google-launches-safety-charter-to-secure-indias-ai-future-flags-online-fraud-and-cyber-threats-480718-2025-06-17?utm_source=recengine&utm_medium=web&referral=yes&utm_content=footerstrip-1&t_source=recengine&t_medium=web&t_content=footerstrip-1&t_psl=False
- https://blog.google/intl/en-in/partnering-indias-success-in-a-new-digital-paradigm/
- https://blog.google/intl/en-in/company-news/googles-safety-charter-for-indias-ai-led-transformation/
- https://economictimes.indiatimes.com/magazines/panache/google-rolls-out-hyderabad-hub-for-online-safety-launches-first-indian-google-safety-engineering-centre/articleshow/121928037.cms?from=mdr